These notes are based on Sebastian’s article about Understanding Reasoning LLMs from his newsletter. It offers valuable insights explained in simpler terms. I highly recommend checking out this newsletter.
Introduction
Reasoning refers to the ability of models to solve problems that require deep analysis before arriving at the correct answer. For simple problems like “5+10”, minimal reasoning is needed. However, more complex tasks, such as solving puzzles, require multiple layers of thought and reasoning. Currently, reasoning models are mostly designed to tackle complex problems, going beyond straightforward computations.
Types of Intermediate Steps in Reasoning Models
Reasoning in LLMs can be broken down into two approaches:
- Explicit Reasoning: The reasoning chain is directly shown in the response.
- Implicit Reasoning: Some models, like OpenAI’s models, run multiple iterations internally without revealing the intermediate steps to the user.
When to Use Reasoning Models?
Reasoning models tend to be more expensive and slower, so it is important to choose when to apply them in a system. For example, it wouldn’t make sense to route a simple sentence like “hello” to a reasoning model. A solution could be implementing a complexity-based LLM router, which directs queries to the appropriate model depending on their complexity.
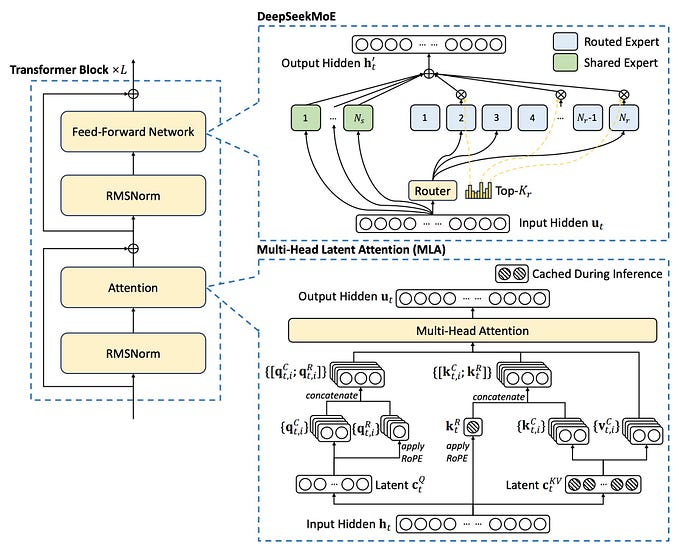
DeepSeek Training Pipeline
DeepSeek has introduced a range of models, each progressively refined for improved reasoning capabilities:
- DeepSeek-R1-Zero: Built on the pre-trained DeepSeek-V3 model, it was trained using reinforcement learning (RL) without supervised fine-tuning (SFT), also known as a cold-start approach.
- DeepSeek-R1: This model builds upon R1-Zero by adding further SFT stages and reinforcement learning, improving the reasoning capabilities.
- DeepSeek-R1-Distill: This model fine-tunes smaller models (Llama 8B and 70B, Qwen 1.5B–30B) using outputs from the larger DeepSeek-R1 671B model, enhancing their reasoning capabilities.
Four Key Methods to Build and Improve Reasoning Models
- Inference-Time Scaling
- In simple terms, inference-time scaling increases computing resources during inference. Techniques include:
- Prompting LLMs with Chain-of-Thought (CoT): This helps provide more context, leading to higher quality responses.
- Generating Multiple Responses: LLMs can generate several responses and select the best one.
- Beam Search: Tracks the top-k most likely sequences at each step and uses a verifier to select the best answer.
- Lookahead Search: Similar to beam search but includes a rollout mechanism to anticipate possible future tokens.
2. Pure Reinforcement Learning (RL)
- DeepSeek-R1-Zero was trained using RL alone, without SFT. The reward models used are:
- Accuracy Reward: Utilizes a logic compiler to evaluate math responses.
- Format Reward: Evaluates responses based on the expected format, assessed by an LLM evaluator.
3. Supervised Fine-Tuning (SFT) + RL
- DeepSeek-R1 integrates RL with SFT. The multi-stage training process includes:
- Cold-start SFT: Data generated by the unsupervised DeepSeek-R1-Zero.
- Instruction Fine-Tuning: Fine-tuned using CoT and knowledge-based SFT examples generated by DeepSeek-V3.
- Reinforcement Learning: Further RL with verifiable rewards (math and coding) and human preference labels for other tasks.
- Final SFT: Instruction fine-tuning with updated CoT examples, boosting performance significantly over the DeepSeek-R1-Zero model.
4.Pure SFT and Distillation
- Distillation involves training smaller models (e.g., Llama 8B, 70B, Qwen 2.5B) with an SFT dataset generated by larger models like DeepSeek-V3 and DeepSeek-R1. The distillation process focuses on improving the reasoning abilities of smaller models by leveraging the larger models’ knowledge.
Conclusion
The field of reasoning in LLMs is rapidly evolving. Through techniques such as inference-time scaling, reinforcement learning, and distillation, models like DeepSeek are pushing the boundaries of what’s possible. Understanding these methods is crucial for developing robust reasoning systems.
🔗 Want to learn more? Follow me on LinkedIn for regular insights into AI and machine learning!