In recent years, machine learning (ML) has made tremendous strides in advancing the field of natural language processing (NLP). Among the most notable contributions are the transformer-based models, such as BERT, GPT-3, and T5, which have set new benchmarks in language understanding and generation tasks. In this article, we will dive into these state-of-the-art models.
Transformer
The Transformer is a deep-learning model that uses a self-attention mechanism. Self-attention works by establishing an amount of importance or relationship between a given word and all its surroundings.
Before going into details, keep in mind that word embedding is a real value numerical representation of a word, this representation encodes the meaning of a word, and this will help to check which other word has a similar encoding. Similar encoding means words are highly related to each other.
Back to self-attention!
For example, if I have this sentence:
“Today I am writing an article about a search engine.”
And let’s say I want to compute the self-attention of the word “article”.
SA(‘article’) = amount of relation between the word “article” and the other words in the sentence (SA = Self-attention).

Each arrow represents an amount of attention between the word “article” and any word in the sentence. In other terms, each arrow shows how much these two words are related to each other. We should note that this is only the attention of one word, we should repeat this step for all other words.
At the end of the process, we will obtain a vector for each word containing numerical values that represent the word + its relationship with the others.
Why did they create self-attention mechanism?
The reason behind creating a self-attention mechanism is because of the limitations found in other basic models.
For example, skip-gram is a model that generates word embeddings. During the training phase of skip-gram, it learns to predict a specific number of words surrounding given a single word as input. Usually, we specify the window size which is how many surrounded words will be given as input.
But the main limitation of this model is that the prediction of a given word will be based only on a limited number of surrounding words. On the other hand, not only self-attention is checking all other words in the sentence, but it also gives a degree of importance to them.
Example: how can an ML model predict the word “river” of the following sentence: Bank of a (river)
Bank and river have completely different meanings, but they are correlated in this sentence. Skip-gram might not be able to predict the correct word because maybe in the training phase, the model didn’t encounter the word river with the bank, or the word river was outside the window size given during training.
For a better understanding of the self-attention mechanism, you can visit these articles :
Now getting back to The Transformer, it has two advantages, the first one is using the self-attention mechanism and the other is parallel computation (because of the matrices and vectors that allow a parallel calculation). It is composed of two components an encoder and a decoder.
The encoder will help us retrieve the best meaningful representation of the input sentence. On the other hand, the decoder will also get the best representation of a given output + the received output from the encoder, this will help the transformer to start understanding the relationship between the words in both the input, the output, and the relation between the input and the output.
For example, if we want to have a translator model from English to French. The transformer will start understanding the relationship between the English words, and the relation between the French words then will try to relate the English words to the French words.
Now I will present the Transformer Architecture with a brief information about each component.
Transformer Architecture
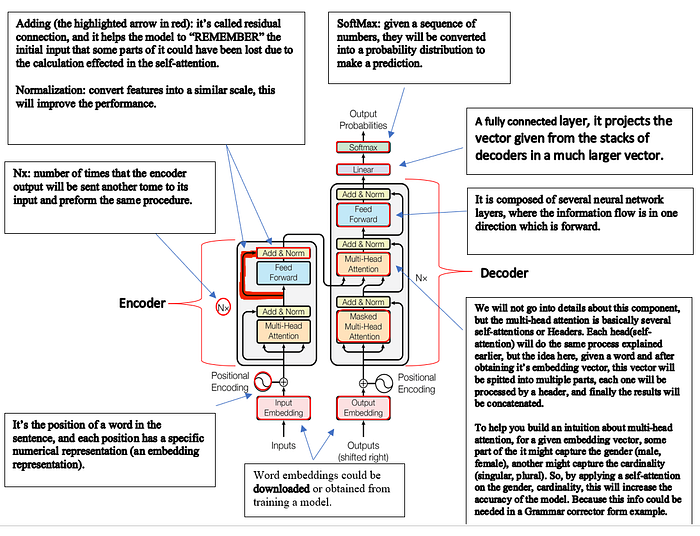
If you are interested in understanding the transformer in-depth, you can read these interesting 4 articles that contain detailed explanations of the transformer: part 1, part 2, part 3, and part 4. Moreover, you can also read famous research papers attention is all you need.
After we explained the transformer, now we can talk about other models that are based on the Transformer.
GPT-3 or Generative pre-trained Transformer
It is based on the Transformer’s decoder (explained above), it is composed of a stack of several decoders.
It is a neural network machine learning model developed by Open AI. After the pre-training phase, the model can take small input and able to generate a lot of words related to the input. It can be used in several applications such as chatbots, summarizers, text classification, translators, and many more.
But how were they able to train the model!?
During the pre-training phase, GPT-3 was like a Vacuum 😜. The model was trained on 45 TB of text 😱, and it was trained to do next-word prediction.

GPT-3 was doing unsupervised learning because all 45 TB of text data are not labeled, so imagine you have this large number of texts, and you can mask any word you want and train the model to predict this word. That’s why GPT-3 is so powerful.
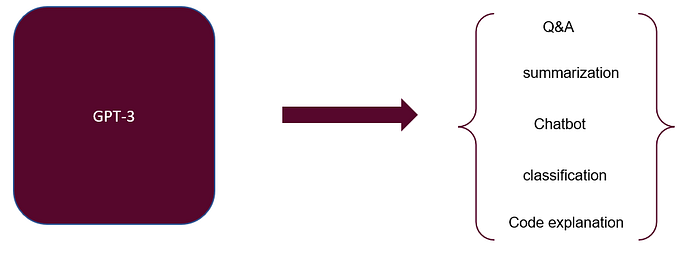
These are some applications of GPT-3, and Open AI has provided 48 example applications of GPT-3, you can check their PLAYGROUND and test this powerful model.
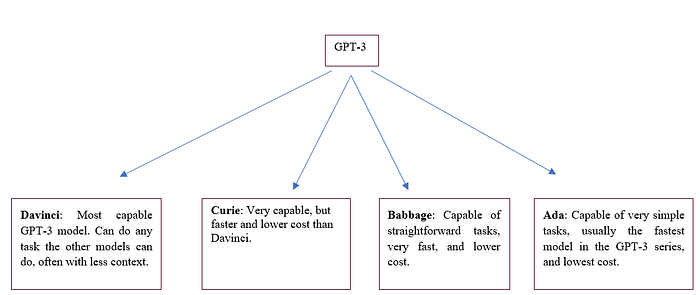
GPT-3 contains 4 models (Davinci, Curie, Babbage, and Ada), and each model has its characteristics. They basically differ in the size of each one, and the number of parameters used during training.
You can learn more about GPT-3 using the following links :
For testing the performance of GPT-3, you can use open AI’s playground.
After we explained GPT-3 model, now we will talk about the most open-source model similar to GPT-3, which is GPT-J.

GPT-J
It is an open-source language model, created by a group of researchers from EleutherAI, it’s a grassroots collective of researchers working to enable open-source AI research. It’s one of the most advanced alternatives to OpenAI’s GPT-3 and has similar performance in different such as chat, summarization, and question answering to name a few. For more info about GPT-J, you can check the explanation and test its performance using this playground.
GPT-J solves the issue of the high cost of GPT-3 (because it is an open source), but the limitation is in the size of the context with a maximum length of 2048 tokens (1500 words). We should mention that we did a comparison of performance between GPT-J and GPT-3 (in the Q&A domain), we gave them both a context and asked several questions related to it , and the performance was almost the same (in some cases, GPT-J was a little bit less accurate than GPT-3).
Now let’s talk about Bert model.

These are some models from the BERT family that I explored. So, what’s BERT?
1) BERT Bidirectional Encoder Representation from Transformers is a paper published by researchers at Google AI Language similar to GPT-3, it takes a component from the transformer, and this time BERT is a stack of the transformer’s encoder.
Bert is used in creating word embeddings because as we said the encoder of a transformer tries to get the best representation of a word/sentence. Using Bert, we can understand the idea/meaning behind a sentence.
During the pre-training phase, the size of the dataset was over 3.3 billion words. Moreover, two techniques were used:
MLM (masked language modeling) and NSP (next sentence prediction).
NSP: A pair of sentences (A and B) were given to the model, and it learns to detect if sentence B succeeds A in the corpus. This helps to learn the relation between sentences.
MLM: some words will be masked, and the model will learn how to predict these words.
We will not go into details about Bert, but if you are interested you can visit the following links: What is Bert? , BERT Neural Network — EXPLAINED! BERT Explained: State-of-the-art language model for NLP
2)Bert large has the same concept as Bert, with minor modifications, such as it contains more blocks of the encoder and more parameters, etc… you can visit this small article about Bert-large and Bert.
3)BART: uses more challenging techniques in the masking during the pre-training phase. In the paper, They stated that it is taught by tampering with text using an arbitrary noise function and then building a model to recreate the original text.
4) Roberta: is an abbreviation for “Robustly Optimized BERT pre-training Approach. This is an improved version of the BERT model in many ways.
The main differences are dynamic masking, more data points (more information fed to the model), the removal of the NSP task (explained earlier), a larger dataset, and a large batch size.
5)Albert: a light Bert, this model is larger than Bert, small than Bert-large. The most differences between Bert and Albert are:
a) Inter-Sentence Coherence Prediction: Albert uses SOP (sentence order prediction instead of NSP. The main difference between the two losses is that NSP checks the topic and the coherence of sentences, on the other hand, SOP checks only the coherence.
b)Cross-layer parameter sharing: parameter sharing between the layers will increase the performance and reduce the redundancy.
c)Factorization of the Embedding matrix: layer embeddings and hidden layer embeddings have the same size in Bert, but different sizes with Albert. They said this will lead to reducing the number of parameters used with a minor drop in performance.
For more info about Albert, you can visit this paper, Visual Paper Summary: ALBERT (A Lite BERT) and Albert-explained-a-lite-bert. md.
After the explanation of the models related to Bert. Now we are going to present the T5 model!!
T5 or Text-to-Text Transfer Transformer
It is a transformer-based architecture, composed of both the encoder and the decoder. It contains 12 transformer blocks with a total of 220 million parameters. The model was pre-trained on a C4 dataset (Colossal Clean Crawled Corpus) with 750 GB of English text. Like Bert, T5 uses MLM, and it learns to predict target words.
Example:

The main difference between Bert and T5 is in the size of tokens (words) used in prediction. Bert predicts a target composed of a single word (single token masking), on the other hand, T5 can predict multiple words as you see in the figure above. It gives the model flexibility in terms of learning the model structure.
More details about T5 can be found in this article.
Finally, I will give a brief explanation on two other models:
The ELECTRA model has been proposed in the paper ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. The generator and discriminator transformer models are trained as part of the new pretraining method called ELECTRA. The generator is trained as a masked language model because its function is to swap tokens in a sequence. Which tokens in the sequence were changed by the generator? The discriminator tells us.
For a brief comparison between Albert, Roberta, and Electra you can check this article.
For more explanation about GPT, BERT, and T5, you can watch a video from Google Cloud tech and read its corresponding blog, also the Google Ai blog contains useful information about T5.
Long Former: is a Bert-like model. Its architecture is a modification of the Transformer. Due to the self-attention operation of standard Transformer-based models, which scale quadratically with sequence length, they are unable to analyze lengthy sequences. Long former employs an attention pattern that grows linearly with sequence length to handle this and makes it simple to process documents with thousands of tokens or more.
And the Long Former takes a maximum of (16k tokens or 4096 words). For more information about the Long Former, you can read this paper, or watch a video that explains the paper. Although this is a good model, but also 4096 words are insufficient for our case.
In conclusion, the field of natural language processing has seen significant advancements in recent years, particularly with the introduction of transformer-based models such as GPT-3, T5 and BERT. And now with the famous model ChatGPT! These models have proven to be highly effective in a wide range of NLP tasks, including language translation, question answering, and text generation. They have also been instrumental in advancing the state-of-the-art in language understanding and representation.
As more and more organizations begin to incorporate these models into their operations, the potential applications for these technologies continue to grow. It will be exciting to see what further developments and breakthroughs will come in the future of AI.
Curious about the latest in AI and ML? Follow me on LinkedIn for fresh insights and updates!
